During the Olympic Games of 1968, Dick Fosbury took gold with a new technique in the high jump. Now all high jumpers use his technique. It’s the only way to be competitive.
The data virtualization technology has become mature and enriches the classic data warehouse architecture. It’s the only way to be able to deliver data to end-users, at business speed.
The Business Need
End-users need information at the speed of their business. Fast, actionable, at the right time and sometimes even real-time. Origin of data and storage technology should not matter. Whether we need internal or external data, data stored in the cloud or on-premise, data should work for you, not against you.
Once available, information users want to have the freedom to consume the data the way they want. This requires that information is integrated, prepared and presented only once for all kinds of information consumption, regardless technology used. What we like to call ‘the data as a service’ concept.

Copyright Denodo
The IT challenge
Today’s explosion of information volumes (social data, sensor data, IOT, …), types (structured / unstructured) and sources (cloud, Hadoop) makes it challenging to support the decision making process. Traditional BI architectures show weaknesses when they need to cover real-time or operational information requirements or need to support an agile delivery process.
Reasons for this lack of flexibility:
As a result, it takes too long to get answers to business users and release new BI functionality. Because IT is not able to follow the demand, business sees no other choice than to build their own solutions. The perfect seed for shadow IT…
The concept of Data Virtualization
Data virtualization defined by Rick Van Der Lans, R20: “Data virtualization is the technology that offers data consumers a unified, abstracted, and encapsulated view for querying and manipulating data stored in a heterogeneous set of data stores.”
Data virtualization integrates data scattered in various silos, without replicating the data. Its functionality is comparable with traditional ETL, but it adds the capability to deliver real-time data integration at lower cost, with more speed and agility.
On top, it offers a single “virtual” data layer that delivers unified data services to support multiple applications and users.
DV platforms and servers typically process data in three steps:
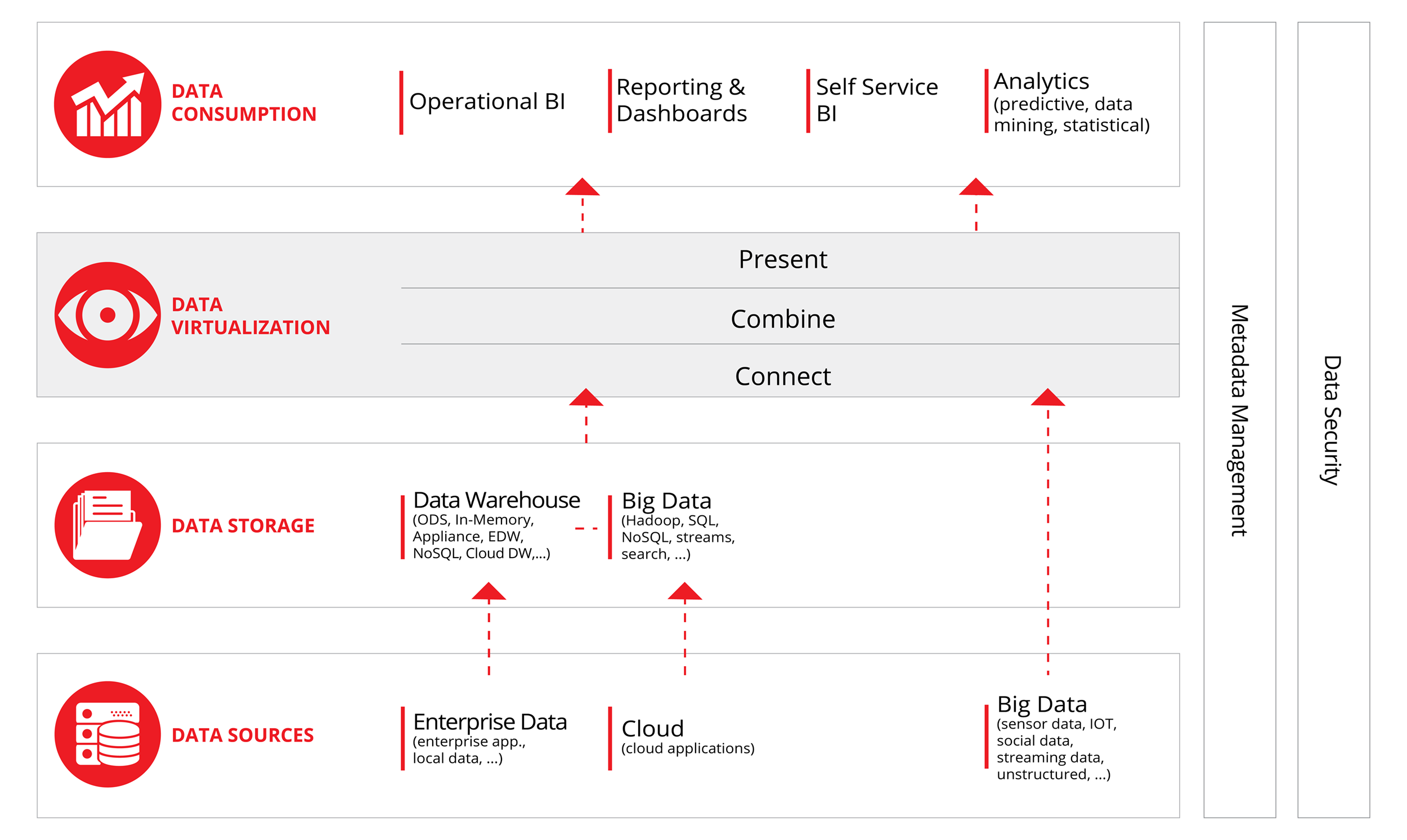
The best DV platforms utilize a combination of real-time query optimization and rewriting, intelligent caching, and selective data movement to achieve superior response and performance against both on-demand pull and scheduled batch push data requests.
Data security and metadata management are incorporated in most DV platforms.
Benefits
Myths
The idea of data virtualization already exists for a few years, but only now technology fully supports the concept. Some DV myths caused a slow adaptation of the technique:
Is one of these myths stopping you from considering the added value of DV for your company? Please contact us and let’s discuss!